Apache Kafka’ya Giriş
Merhaba arkadaşlar! Bugün sizlere büyük veri dünyasının gözdesi Apache Kafka’dan bahsedeceğim. Kafka, yüksek hacimli veri akışlarını gerçek zamanlı olarak işlemek ve yönetmek için kullanılan, dağıtılmış bir akış işleme platformu. Başlangıçta LinkedIn tarafından geliştirilen bu harika araç, şimdi Apache Software Foundation tarafından açık kaynaklı olarak sunuluyor.
Kafka’nın Temel Bileşenleri
Kafka’nın yapısını anlamak için öncelikle bileşenlerine göz atalım:
- Topic (Konu): Mesajların kategorize edildiği yerdir. Her konu, belirli bir veri türünü veya veri akışını temsil eder.
- Producer (Üretici): Veriyi Kafka’ya gönderen bileşenlerdir. Üreticiler, belirli konulara veri gönderirler.
- Consumer (Tüketici): Veriyi Kafka’dan okuyan bileşenlerdir. Tüketiciler, belirli konuları dinleyerek veriyi alırlar.
- Broker: Kafka’nın çalıştığı sunuculardır. Veriyi depolar ve yönetirler.
- Zookeeper: Kafka’nın dağıtılmış yapısını yönetmek için kullanılan koordinasyon servisidir.
Kafka’nın Özellikleri ve Avantajları
Kafka’nın neden bu kadar popüler olduğuna bir bakalım:
- Yüksek Performans: Kafka, yüksek hacimli veri akışlarını düşük gecikme ile işleyebilir. Bu da onu gerçek zamanlı uygulamalar için ideal kılar.
- Dağıtılmış Mimari: Kafka, veri güvenilirliğini ve ölçeklenebilirliğini sağlamak için dağıtılmış bir yapı kullanır.
- Kalıcılık: Kafka, verileri disk üzerinde tutarak veri kaybını önler ve gerektiğinde geçmiş verilere erişim sağlar.
- Gerçek Zamanlı İşleme: Kafka, verileri anlık olarak işleyerek gerçek zamanlı analiz ve raporlama yapmayı mümkün kılar.
Kafka’nın Kullanım Alanları
Peki, Kafka’yı nerelerde kullanabiliriz? İşte bazı kullanım alanları:
- Gerçek Zamanlı Analitik: Büyük veri analitiği için verilerin anlık olarak toplanması ve işlenmesi.
- İzleme ve Günlük Yönetimi: Uygulamaların ve sistemlerin izlenmesi, günlük kayıtlarının toplanması ve analiz edilmesi.
- Veri Entegrasyonu: Farklı veri kaynaklarının entegrasyonu ve senkronizasyonu.
- Mesajlaşma: Mikro hizmetler arasında iletişim kurmak için güvenilir ve hızlı bir mesajlaşma altyapısı sağlama.
Örnek Uygulama
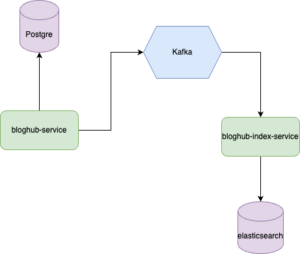
Uygulamamıza şöyle bir senaryo ekliyoruz. Medium gibi bir web uygulaması düşünelim ve bir makale yayınlandık için ilişkisel veritabanına kayıt edeceğiz ve sonra arama işlemlerini
daha hızlı yapabilmek için hem de asenkron olarak elasticsearch uygulamasına kayıt edeceğiz. Mimarimiz aşağıdaki gibi olacaktır.
Öncelikle aşağıdaki docker-compose.yml dosyasıyla bir kafka ayağa kaldıralım.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
version: '2' services: zookeeper: image: wurstmeister/zookeeper:latest ports: - "2181:2181" kafka: image: wurstmeister/kafka:latest ports: - "9092:9092" expose: - "9093" environment: KAFKA_ADVERTISED_LISTENERS: INSIDE://kafka:9093,OUTSIDE://localhost:9092 KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: INSIDE:PLAINTEXT,OUTSIDE:PLAINTEXT KAFKA_LISTENERS: INSIDE://0.0.0.0:9093,OUTSIDE://0.0.0.0:9092 KAFKA_INTER_BROKER_LISTENER_NAME: INSIDE KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181 KAFKA_CREATE_TOPICS: "my-topic:1:1" volumes: - /var/run/docker.sock:/var/run/docker.sock |
Producer
|
1 2 3 4 5 6 7 8 |
<dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka</artifactId> </dependency> |
|
1 2 3 4 5 |
spring.kafka.bootstrap-servers=localhost:9092 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
@Configuration public class KafkaConfig { @Bean public ProducerFactory<String, Object> producerFactory() { Map<String, Object> configProps = new HashMap<>(); configProps.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); configProps.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class); configProps.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class); return new DefaultKafkaProducerFactory<>(configProps); } @Bean public KafkaTemplate<String, Object> kafkaTemplate() { return new KafkaTemplate<>(producerFactory()); } } |
KafkaTemplate objesi üzerinden send methodu ile hangi topic’e göndereceğimizi belirtmemiz yeterli. Zaten KafkaConfig class’ında KafkaTemplate bean’ini oluşturmuştuk.
Fakat dikkat edilmesi gereken kısım bizim kafka’ya obje yazmak istememizle başlıyor. KafkaConfig class’ında da göreceğmiz üzere ProducerFactory ve KafkaTemplate bean olarak tanımlarken
serialization kısmında JsonSerializer kullandık ve <key,value> tanımlarımız <String, Object> olarak gerçekleştirdik.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
@Component @RequiredArgsConstructor @Slf4j public final class KafkaProducer { private final KafkaTemplate<String, Object> kafkaTemplate; public void sendBlog(Blog blog) { log.info("blog gönderildi: {}", blog.getId()); kafkaTemplate.send(KafkaTopicConstants.BLOG_INDEX_TOPIC, blog); } } |
Service
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
@Service @RequiredArgsConstructor public class BlogService { private final BlogRepository blogRepository; private final UserClientService userClientService; private final KafkaProducer kafkaProducer; public BlogResponse createBlog(BlogSaveRequest request) { UserResponse foundUser = userClientService.getUserByEmail(request.getEmail()); if (foundUser == null) { throw new BlogHubException(ExceptionMessages.USER_NOT_FOUND); } Blog blog = prepareBlog(request, foundUser); blogRepository.save(blog); kafkaProducer.sendBlog(blog); return BlogConverter.toResponse(blog); } } |
Consumer
ConsumerConfig
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
@Configuration public class KafkaConsumerConfig { @Value("${spring.kafka.bootstrap-servers}") private String bootstrapServers; @Value("${kafka.group-id}") private String groupId; @Bean public ConsumerFactory<String, Blog> consumerFactory() { Map<String, Object> configProps = new HashMap<>(); configProps.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers); configProps.put(ConsumerConfig.GROUP_ID_CONFIG, groupId); configProps.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); configProps.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, JsonDeserializer.class); configProps.put(ErrorHandlingDeserializer.VALUE_DESERIALIZER_CLASS, JsonDeserializer.class.getName()); configProps.put(ErrorHandlingDeserializer.KEY_DESERIALIZER_CLASS, StringDeserializer.class.getName()); configProps.put(JsonDeserializer.TRUSTED_PACKAGES, "*"); configProps.put(JsonDeserializer.USE_TYPE_INFO_HEADERS, false); return new DefaultKafkaConsumerFactory<>(configProps); } @Bean public ConcurrentKafkaListenerContainerFactory<String, Blog> kafkaListenerContainerFactory() { ConcurrentKafkaListenerContainerFactory<String, Blog> factory = new ConcurrentKafkaListenerContainerFactory<>(); factory.setConsumerFactory(consumerFactory()); factory.setCommonErrorHandler(new DefaultErrorHandler()); return factory; } } |
|
1 2 3 4 5 |
configProps.put(JsonDeserializer.TRUSTED_PACKAGES, "*"); |
Bu ayar, hangi paketlerin güvenilir olduğunu belirler. JsonDeserializer, gelen JSON verilerini Java nesnelerine dönüştürmek için kullanılır.
Güvenlik amacıyla, yalnızca belirli paketlerden gelen verilerin deseralize edilmesine izin verilebilir. * değeri, tüm paketlerin güvenilir olduğunu ve
tüm paketlerden gelen verilerin deseralize edilebileceğini belirtir.
|
1 2 3 4 5 |
configProps.put(JsonDeserializer.USE_TYPE_INFO_HEADERS, false); |
Bu ayar, JSON verilerinin deseralize edilmesi sırasında tip bilgisi başlıklarının kullanılıp kullanılmayacağını belirler.
Kafka mesajları genellikle bir başlık (header) kısmına sahiptir ve bu başlıklar ek bilgiler içerebilir. USE_TYPE_INFO_HEADERS ayarı false olarak ayarlandığında,
deseralizer tip bilgisi başlıklarını kullanmaz ve JSON verilerini direkt olarak deseralize eder.
Service
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
@Component @Slf4j @RequiredArgsConstructor public class KafkaConsumer { @KafkaListener(topics = KafkaTopicConstants.BLOG_INDEX_TOPIC, groupId = "${kafka.group-id}") public void listen(Blog blog) { log.info("Received Messasge: {}", blog); } } |
Kaynak
Faydalı olması dileğiyle.