
HPE ve NVIDIA’nın ortaklaşa Avrupa genelinde düzenlediği GenAI Roadshow turunun son durağı olan İstanbul bacağı, 5 Aralık’ta JustWork@İstanbul’da oldukça yüksek bir katılımla yapıldı. Etkinliğin ana konusu büyük ölçekte kendi veri merkezimizde üretken yapay zeka projesi yapmanın zorluklarını ve bunları aşmanın yollarını paylaşmak olmakla birlikte, konu konuyu açınca veri merkezi soğutmadaki yeniliklere kadar pek çok detay konuşuldu. “kendi veri merkezimizde” yazarken özellikle kalın harflerle yazdım, çünkü etkinlikte anlatılan hemen herşey “onpremise” yaklaşımı öne çıkarıyor, hatta bulutta ChatGPT 40 vs. Meta’nın açık-kaynak yapay zeka modellerinin onpremis uzun dönem maliyet kıyasmasının detayları da konuşuldu.
Açılış konuşmasını HPE Türkiye başkanı Güngör bey yaptı. Davos’ta bu sene en çok konuşulan konuların başında veriden değer üretme olduğunu ve bu rolün artık yapay zekada olduğunu paylaştı.

HPE’nin son dönemde yaptığı satın alımların ve iş birliklerinin hep aynı amaca hizmet ettiğini ve bu doğrultuda ilerlemeye de devam edeceklerini sayısal verilerle ifade etti

Bir yapay zeka projesine adım atmanın ilk koşulu “use case” yani kullanım alanı bulmak. Bu adımdan sonra yapay zekanın yaşam döngüsünü planlama geliyor. Bundan sonraki adım oldukça planlı ve dikkatli atılmalı çünkü gerekli yazılım ve donanım yatırımının planlanması söz konusu
Avrupa’da HPE’nin yapay zeka ve HPC satışlarından sorumlu olan Martin Herrmann, Güngör beyden sonra sahneye çıktı ve HPE’nin yapay zeka yaklaşımının detaylarını paylaştı

Etkinliğin geri kalanında sahneye çıkacak arkadaşlarını kısaca tanıttıktan ve günün ajandasını paylaştıktan sonra sahneyi onlara bıraktı


Bugün pek çok kurum yapay zeka ile ilgili “bir proje” yapmaya çalışıyor, ancak nerden başlasam, buluta mı çıksam, kendi veri merkezimdeki yapsam, kendi veri merkezimde yapsam nasıl bir yatırım yapmam lazım,.. gibi bir sürü o an yanıtını kolayca veremediği soruyla yüzleşiyor

İlgi eskiden popüler olan veri/büyük veriden, günümüzde veriden değer çıkarmak misyonunu üstlenen yapay zekaya kaymış durumda. Chris geçmişten bu yana HPE olarak bu doğrultuda yaptıkları yatırımları paylaştı

ChatGPT ile birlikte hayatımıza insanlarla insan gibi konuşarak iletişim kuran yapay zeka kavramı girdi. Eskiden bilgisayarlarla iletişim kurmak için biz onun dilini öğrenirdik (kodlama dediğimiz basitçe bu aslında), şimdi ise LLM sayesinde bilgisaylarlar bizim dilimizi öğrenip, bizimle kendi dilimizle iletişim kuruyor

Chris başlangıçtan uygulamaya kadar bir LLM nasıl oluşturulurun detaylarını paylaştı
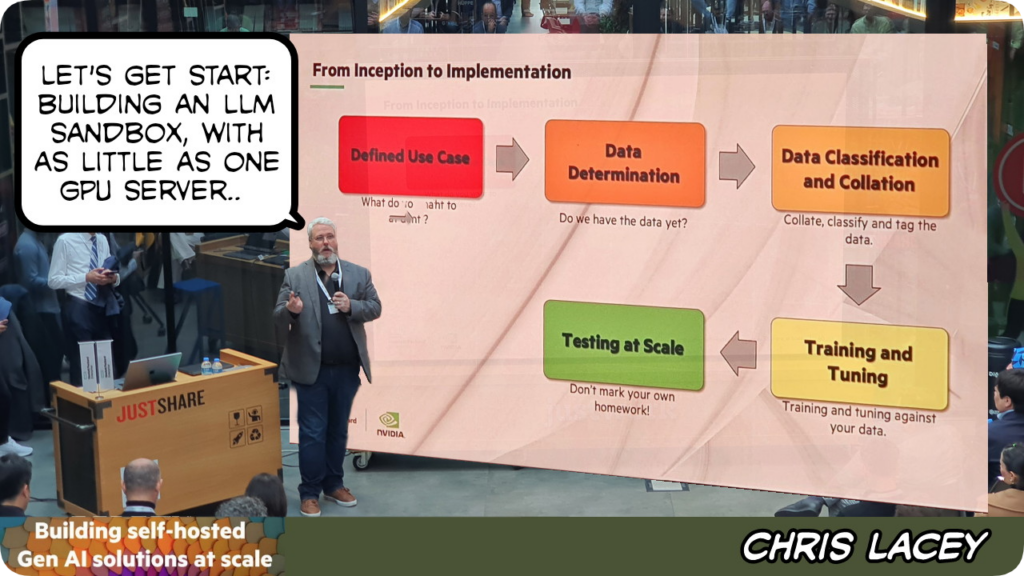
LLM denince ML yani makina öğreniminden söz etmemek olmak, ikisi yıldırım ve gök gürültüsü gibi birbirini takip eden iki ayrılmaz kavram. Yapay zeka için LLM gerekiyor, LLM için ML gerekli, ML için de üç temel bacağı olan sağlam bir yatırım gereksinimi söz konusu: altyapı, platform ve modeller
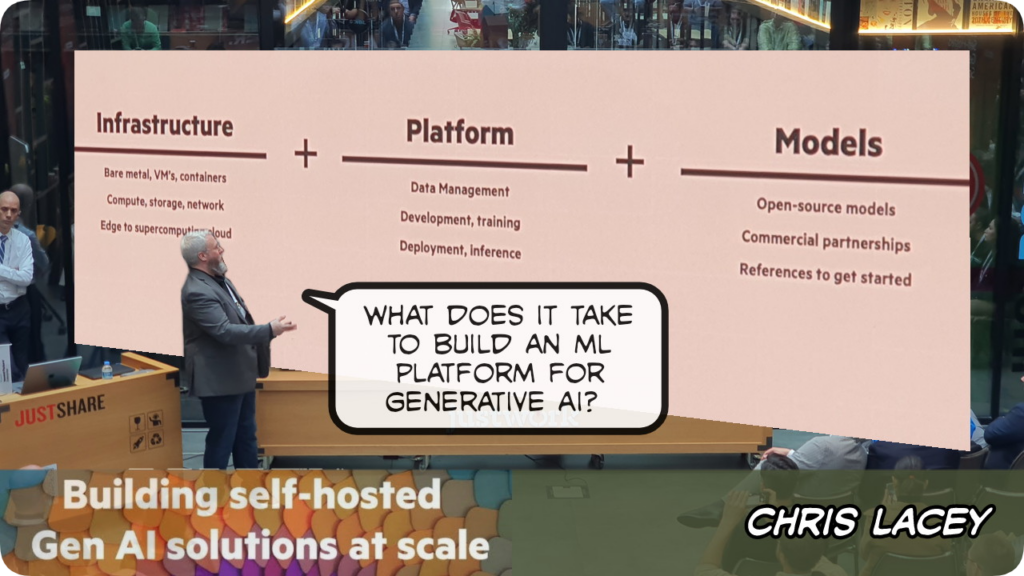
Chris yapay zeka uygulamalarını kendi veri merkezlerimizde çalıştırabilmek için gerekli altyapıdan söz ederken ilk olarak sunucu/GPU gereksinimlerinden söz etti, sonra nasıl bir network ve storage altyapısı olması gerekliliği paylaştı..

..geleneksel NAS/NFS tabanlı bir storage ile yapay zeka uygulamalarının ihtiyaç duyduğu storage altyapısı farklılıklarını detaylandırdı

Chris HPE’nin sunduğu yapay zeka altyapı seçenekleri hakkında paylaşımlarda bulundu

Eskiden NVIDIA denince hepimizin aklına oyun bilgisayarlarına takılan performanslı ekran kartları gelirdi, şimdilerde ise NVIDIA denilince ilk akla gelen GPU ve yapay zeka oluyor.
Etkinliğin başından bu yana konuşanlar HPE’den oldu, Chris’ten sonra sahneye NVIDIA’da kurumsal müşterilerden sorumlu Ziad çıktı. Yapay zeka konusunda HPE-NVIDIA iş birliğinin detaylarından söz etti. Küçükten büyüğe her ölçekteki ihtiyaca uygun çözüm sunduklarını paylaştı..

..bunu esnek yaklaşımı da HPE Greenlake Cloud* ile sağladıklarının altını çizdi

Ziad’tan sonra Chris de HPE Greenlake Cloud’un yapay zeka altyapı ihtiyaçlarını karşılamada nasıl esneklik sağladığını detaylandırmaya devam etti

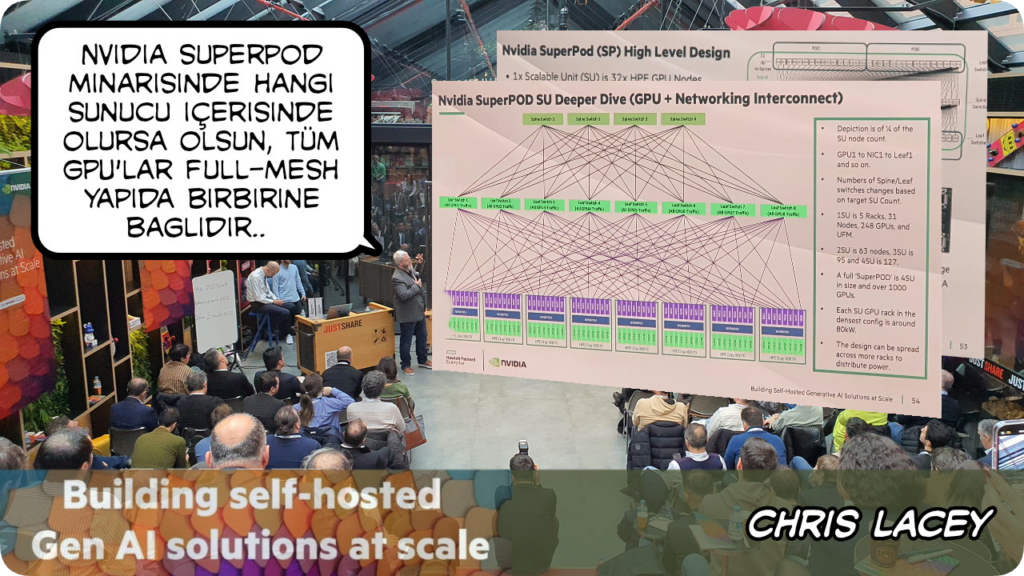
Yapay zeka uygulamalarını hızlandırmak ve ölçeklendirmek için tasarlanmış, anahtar teslimi bir altyapı çözümü olan NVIDIA SuperPOD’un sağladığı avantajları anlattı Chris. NVIDIA SuperPod’un, büyük veri kümeleri üzerinde karmaşık derin öğrenme modellerini eğitmek için gereken muazzam hesaplama gücünü nasıl karşıladığını da detaylıca paylaştı
Yapay zeka ve HPC uygulamarının üzerinde koştuğu sunucuların geleneksel sunuculara göre çok daha fazla güç çekmeleri ve dolayısıyla çok daha yüksek soğutmaya ihtiyaç duymaları, geleneksel veri merkezi iklimlendirme sistemlerinin yetersiz kalmasına neden oluyor
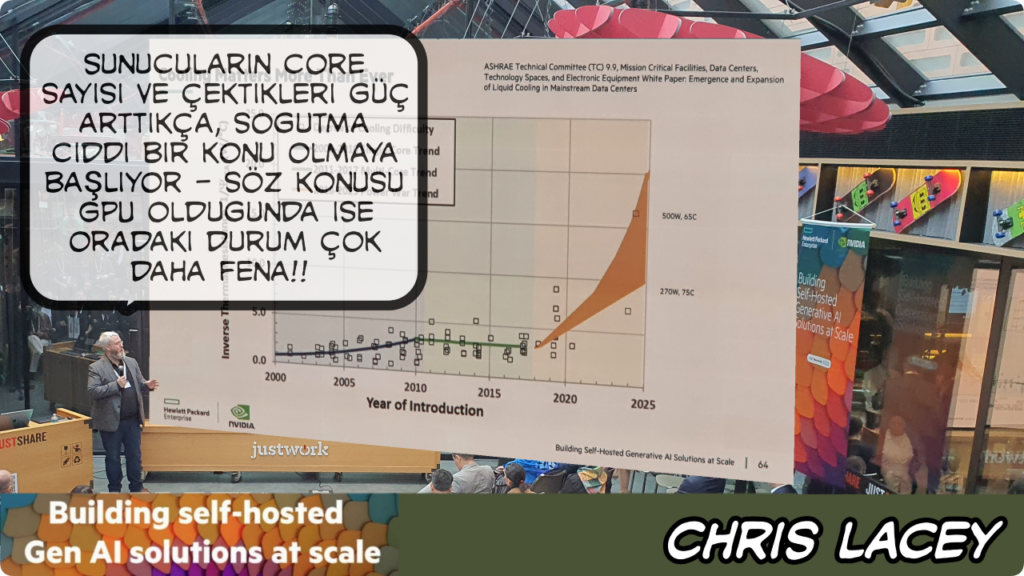
Chris soğutma ihtiyacındaki artışı Uptime Institute verileri ile destekleyerek anlattı
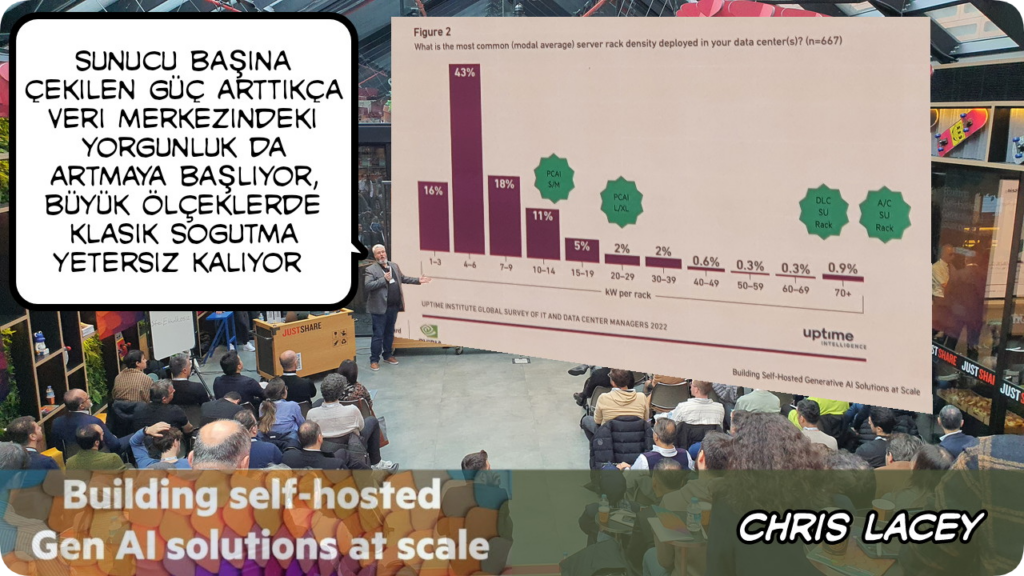
Veri merkezi soğutma şu an yaygın olarak veri merkezindeki sıcak havayı ortamdan alıp, ortama soğuk hava vermeye ve bu havayı içeride sirküle etmeye dayanıyor. Yeni nesil ihtiyaçlar için yeni nesil soğutma gerekliliği var ve bunu en iyi adresleyenlerden birisi de HPE’nin direk sıvı soğutma sistemi HPE DLC olduğunu paylaştı Chris


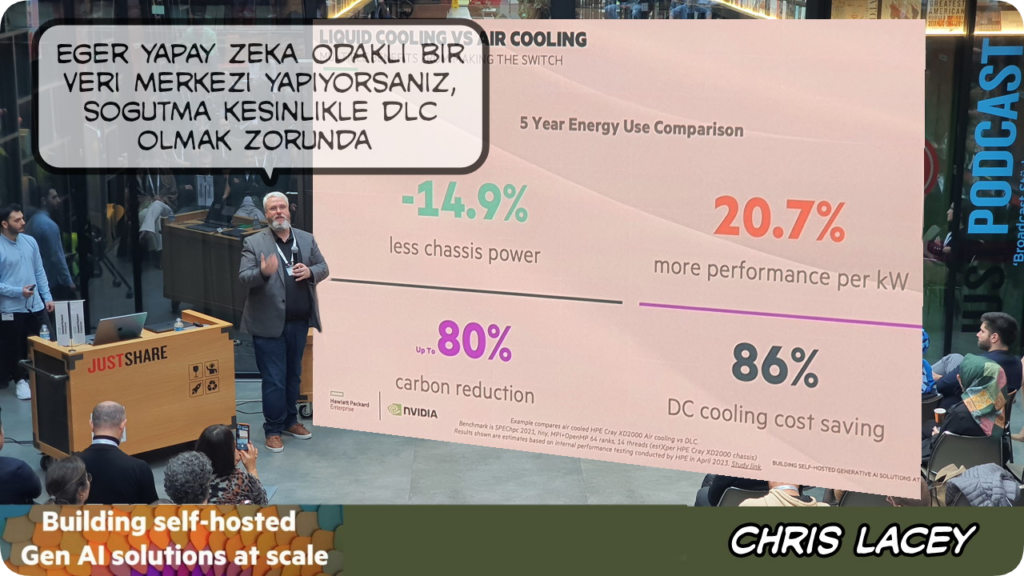
Chris geleneksel veri merkezi iklimlendirme ve HPE sıvı soğutmalı iklimlendirmenin 5 yıllık TCO olarak maliyetlerinin bir kıyaslamasını paylaştı – %80 daha az çevreyi kirletme ve %86 enerji tasarrufu oldukça etkileyici!
HPE’nin sunucularını bilmeyen yoktur, Türkiye’de hemen her veri merkezinde illaki DL380 vardır. Chris HPE’nin SuperComputer alanında da lider bir üretici olduğunu, bu konumunun HPE’yi yapay zeka donanım tedariğinde de öne çıkardığını paylaştı

Etkinlik öncesi çay/kahve içerken Tjerk ile tanışıp, bolca sohbet etme imkanı buldum. HPE’de EMEA bölgesinden sorumlu iş geliştirme yöneticisi olarak çalışıyor. Çok sıcak kanlı ve samimi birisi Tjerk. Yapay zeka projelerinin ancak %12’sinin başarılı bir şekilde sonuçlandığını paylaştı – oldukça çarpıcı bir istatistik!


Tjerk yapay zeka projelerinin başarı oranını artırmak için güvenilir bir yol arkadaşı ile yola çıkamanın öneminden söz etti, HPE ve NVIDIA olarak bu yol arkadaşlığına talip olduklarını paylaştı
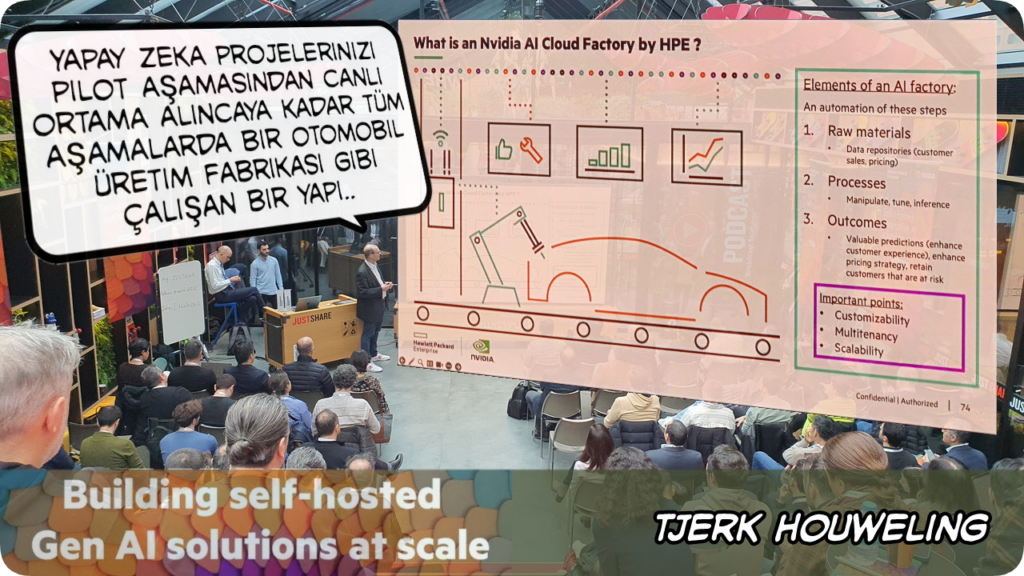
ChatGPT gibi bulut tabanlı bir yapay zeka hizmeti ile yola çıkamanın başlangıçta uygun maliyetli gibi geleceğini, ancak projenin ilerleyen aşamalarında bu maliyetin onprem bir çözümün maliletinin çok üzerine çıkabileceğini, bu maliyet artışının da projeleri başarız kılan faktörlerden birisi olduğunu söyledi
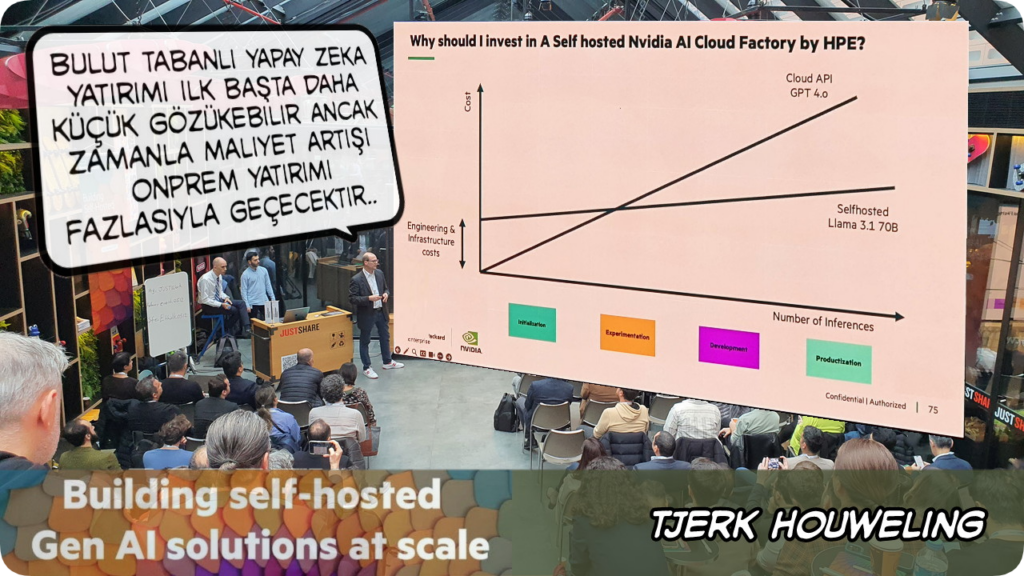
Onprem yatırımla bulut tabanlı yatırımın örnek bir maliyet karşılaştırmasını paylaştı


Tjerk, ön görülebilir ve yönetilebilir bir maliyetle, güvenlikten ödün vermeden kendi veri merkezimizde yapay zeka altyapısı kurmada HPE-NVIDIA ortaklığından faydanlanmanın avanlajlarını anlattı

HPE’de machine learning engineer olarak alışan Hana, diğer konuşmacılar gibi teorik bilgiler vermenin yanı sıra birkaç tane canlı machine learning demosunu da paylaştı


Yapay zekanın olmazsa olmaz temel bir bileşeni olan machine learning dünyasına nasıl adım-adım girilebileğini örnek senaryolar üzerinden paylaştı


Hana, HPE Machine Learning Platform ile ML projelerinin kolay ve hızlı bir şekilde nasıl hayata giçirilebileceğini anlattı

Hana’dan sonra tekrar sahneye çıkan Zaid, yönetilen servis olarak üretken yapay zeka ile açık-kaynak yapay zeka konumlandırmayı kıyasladı

Bulut, veri merkezi ve iş istasyonları gibi çeşitli ortamlarda yapay zeka modellerinin dağıtımını kolaylaştıran bir yazılım platformu olan NVIDIA NIM, farklı yapay zeka modelleri için optimize edilmiş ve kolayca bir araya getirilebilir mikro hizmetler olarak konumlandırılmış bağımsız yazılım birimlerinden oluşuyor – bu sayede NVIDIA NIM ile farklı ihtiyaçlara göre özelleştirilebilir yapay zeka çözümleri oluşturmak oldukça kolaylaşıyor ![]()

Ziad, NVIDIA NIM kullanarak hemen her alanda yapay zeka projeleri yapmanın geleneksel yaklaşımlara göre çok daha hızlı ve kolay olduğunu paylaştı

NVIDIA NIM ile sadece hızlı bir şekilde yapay zeka projesi yapmakla kalmaz, ortaya çıkan yapay zeka projesinin performansı da geleneksel yöntemlerle yapılanlara göre 4-5 kat daha yüksek olur şekilnde oldukça etkileyici bir iddiada bulundu – hızlı geliştir & performanslı çalıştır!
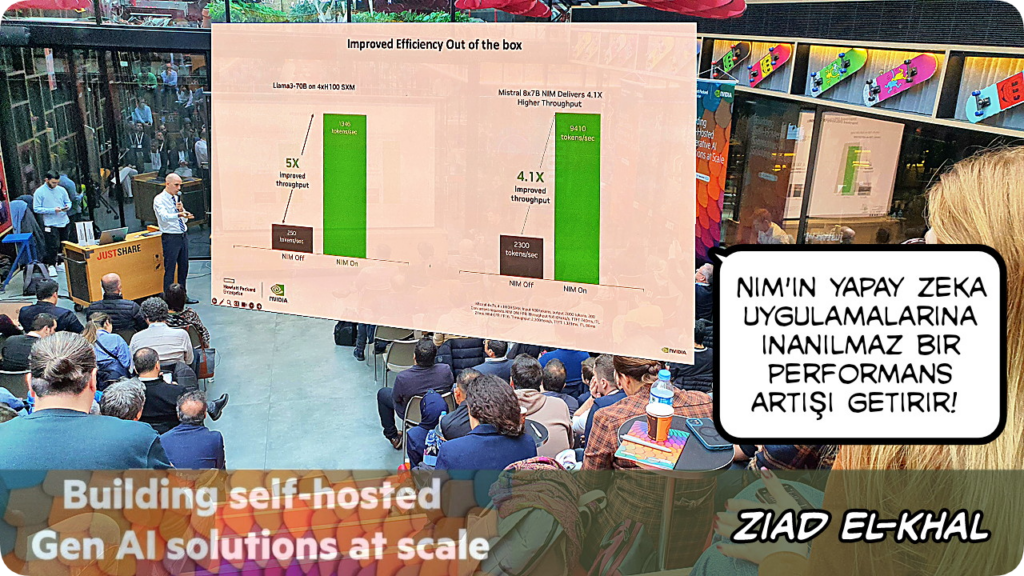

Ziad, NVIDIA API katalog kullanarak büyük ölçekli yapay zeka projelerini geliştirmenin avantajlarını paylaştı

Zaid, NVIDIA Enterprise AI’ın yapay zeka uygulamalarını geliştirme ve dağıtma süreçlerini hızlandırmak için tasarlanmış kapsamlı bir bulut tabanlı yazılım platformu olduğunu ve bu platformun, veri bilimcilerin ve geliştiricilerin üretken yapay zeka dahil olmak üzere endüstriyel düzeyde yapay zeka uygulamalarını kolayca oluşturmasına ve dağıtmasına olanak tanıdığını..
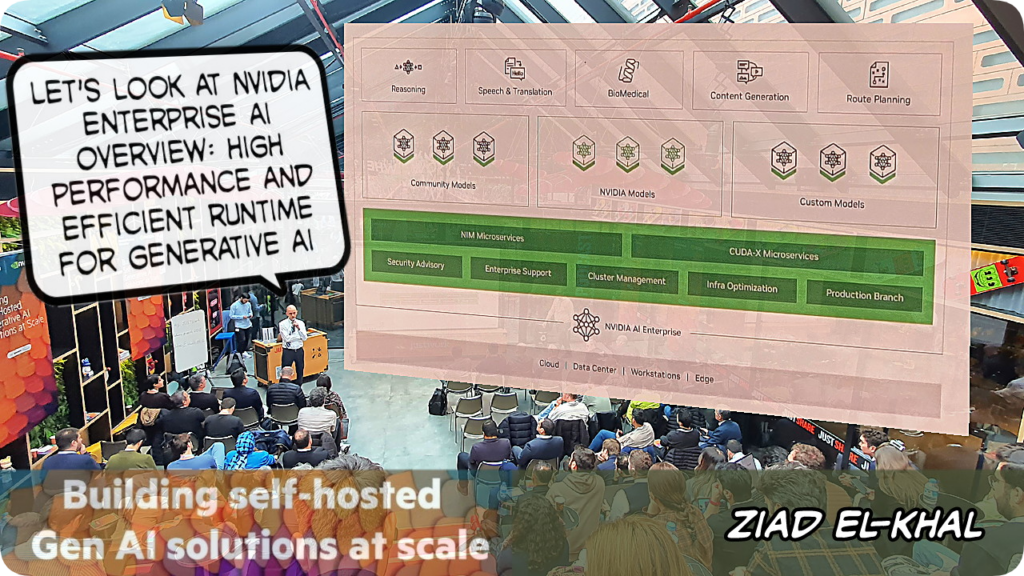
..ayrıca hızlı ve verimli yapay zeka geliştirme, ölçeklenebilir esnek altyapı, güvenilirlik & güvenlik, endüstriyel seviyede uygulamalar yapabilme, düşük sahip olma maliyeti gibi avantajları olduğunu paylaştı

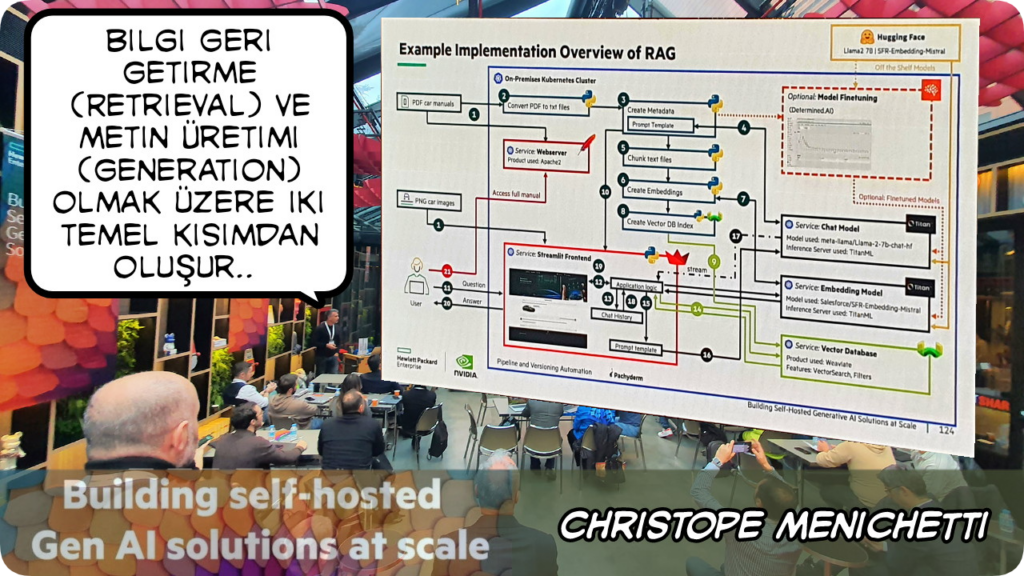
HPE’de AI Solution Architect olarak çalışan Christophe Menichetti, bir yapay zeka projesinde en zorlayıcı kısımların başında LLM’in geldiğini paylaştı


Büyük dil modelleri (LLM) ile bilgi geri alma sistemlerinin bir araya getirilmesiyle oluşturulan bir yapay zeka yaklaşımı olan RAG veya Türkçe açılımıyla “Getirme Destekli Üretme”, LLM’lerin ürettiği yanıtların daha doğru, güncel ve bilgiye dayalı olmasını sağlar. Christophe, bunu bir örnek üzerinden anlaşılır bir şekilde anlattı
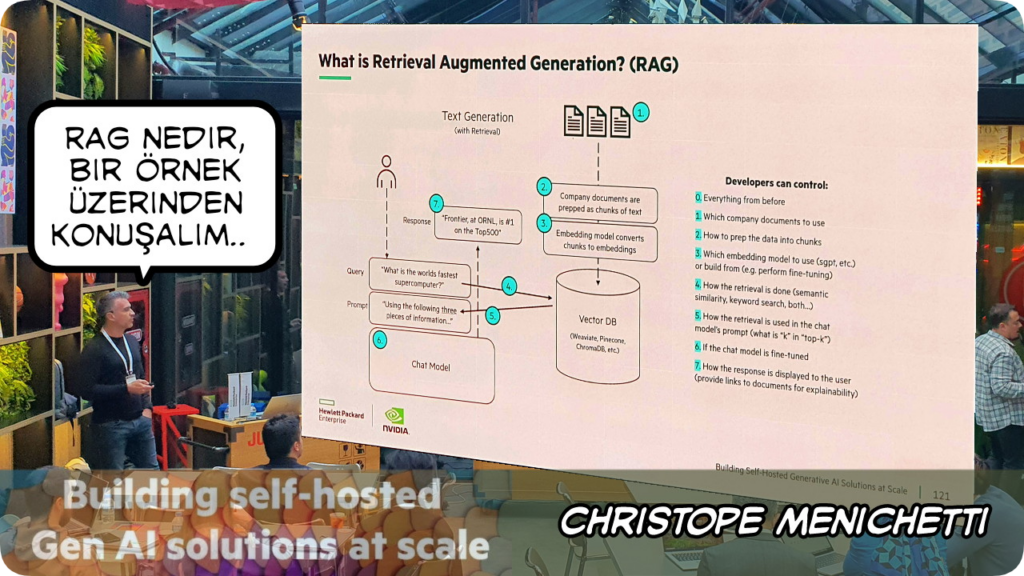
RAG nasıl çalışır?
- Soru Alımı: Kullanıcı bir soru sorar.
- Bilgi Getirme: Model, soruyla ilgili alakalı bilgileri bir bilgi tabanından veya internetten getirir.
- Üretme: Getirilen bilgiler ışığında, LLM soruyu yanıtlamak için en uygun metni üretir.
RAG neden önemli?
- Daha doğru yanıtlar: LLM’ler, gerçek dünyadaki bilgiye erişerek daha doğru ve güvenilir yanıtlar üretebilir.
- Güncel bilgiler: Sürekli güncellenen bilgi kaynakları sayesinde, LLM’ler her zaman en güncel bilgilere dayanarak yanıt verir.
- Hallüsinasyonların azaltılması: LLM’lerin bazen gerçek olmayan bilgiler üretme eğilimi olan “hallüsinasyon” sorununu azaltır.
- Karmaşık soruların yanıtlanması: Karmaşık ve çok adımlı soruları yanıtlamak için gerekli bilgileri bir araya getirerek daha kapsamlı yanıtlar sunar.
LLM eğitiminin temel adımları neler dersek:
-
Veri hazırlığı:
- Veri Toplama: İnternetten, kitaplardan, makalelerden veya özel veri tabanlarından yeni veriler toplanır.
- Temizleme: Toplanan verilerdeki hatalar, tutarsızlıklar ve gürültüler temizlenir.
- İşleme: Veriler, modelin anlayabileceği bir formata (örneğin, tokenize edilmiş metin) dönüştürülür.
-
Model eğitimi:
- Parametre Ayarlama: Modelin öğrenme hızını, batch boyutunu ve diğer hiperparametreleri ayarlanır.
- Eğitim Döngüsü: Model, hazırlanan verilere göre eğitilir. Bu süreçte, modelin tahminleri gerçek değerlerle karşılaştırılır ve modeldeki parametreler bu farkı en aza alacak şekilde güncellenir.
- Kayıp Fonksiyonu: Modelin ne kadar iyi performans gösterdiğini ölçmek için bir kayıp fonksiyonu kullanılır.
-
Değerlendirme:
- Gelişim Takibi: Modelin her eğitim adımındaki performansı değerlendirilir.
- Overfitting Önleme: Modelin eğitim verilerine aşırı uyum sağlaması (overfitting) önlenir.
- Genelleme Kabiliyeti: Modelin yeni, görülmemiş verilere ne kadar iyi uyum sağladığı test edilir.
-
İnce ayarlama (Fine-tuning):
- Özel Görevler: Model, belirli bir göreve (örneğin, soru cevaplama, çeviri) daha iyi uyum sağlaması için ince ayarlanır.
- Daha Az Veri: İnce ayarlama için genellikle daha az veri kullanılır.

Etkinlerde ilk elden en güncel bilgileri almak harika, ancak dostlarla karşılaşmak ve sohbet edebilme imkanı paha biçilemez!!


Beni bu harika etkinliğe şahsen davet eden Mert Sarıkaya’ya bir de buradan teşekkürlerimi iletmek istiyorum: Teşekkürler Mert!