
Makine öğrenmesi ile ilişkili veri bilimciliği, veri mühendisliği, veri çevirmenliği gibi iş ilanları bugünlerde çokça rahbet görmekte. Fakat yetenek yokluğu sebebiyle arz ve talep arasında ciddi uçurumlar bulunuyor. Yazılım mühendisliği evveliyatına sahip kişileri makine öğrenmesi çalışmaları için en potansiyel adaylar olarak görüyoruz. Fakat yine de yazılımcılık ve makine öğrenmesi uygulayıcılığı arasında çok katı farklar bulunmakta. Bu yazıda makine öğrenmesi konularında çalışacak veri bilimcileri ile yazılımcıların ne gibi farklılıkları olduğuna değinecek ve yazılımcıların bu yeni alana nasıl adapte olabileceğine odaklanacağız.

Kodlama
Yapay zeka ve makine öğrenme çalışmaları kodlama, matematik ve iletişim yeteneklerine sahip olmayı gerektirmektedir. Yazılımcıların hali hazırda güçlü kodlama yeteneklerine sahip olduklarını biliyoruz. Fakat matematik odaklı düşünce konusunda eksiklikleri olabilmekte. Kod bazlı perspektiften matematik bazlı düşünce setine geçiş ilk ihtiyaç.
Basit bir sinir ağı hücresini göz önüne getirin. Girdiler kendilerine ait ağırlıklar üzerinden hücreye dahil olmakta. Burada ağın çıktısını hesaplamak için girdiler ve bağlı oldukları ağırklıkları çarpmamız gerekiyor. Bu çarpımların toplamı net girdiyi verecekken, net girdi bir aktivasyon fonksiyonuna girerek net çıktıyı oluşturmakta. Aktivasyon fonksiyonu olarak basamak fonksiyonunu düşünebilirsiniz. Net girdi eşiğin üzerinde ise tetikle, aksi takdirde tetikleme.
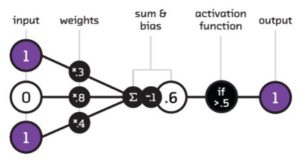
Bunu kodlamaya dökmek istediğimizde yazılımcılar olarak hemen elimiz for döngüleri kurmaya gidiyor. Girdiler ve ağırlıklar bir dizide saklanıyor olsun. Girdinin boyutunda bir for döngüsü ile aynı indeksli girdi ve ağırlık çarpılıp bir toplam değişkenine eklenirse net girdiyi hesaplayabiliriz. Bu algoritmayı python diline döktüğümüz zaman aşağıdaki kod bloğuna benzer bir kod parçası iş görecektir.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
import numpy as np inputs = np.array([1,0,1]) weights = np.array([0.3, 0.8, 0.4]) sum = 0 for i in range(inputs.shape[0]): sum = sum + inputs[i] * weights[i] print(sum) |
Bu yaklaşım tamamıyle çalışırken girdinin boyutu arttıkça çalışması daha uzun sürecektir. Her bir değişkenin farklı bir bellek slotunda olması sebebiyle çözüm çok optimum olmamaktadır. Halbuki makine öğrenmesi uygulayıcıları bu probleme şu şekilde yaklaşmaktadır.
|
1 2 3 4 5 |
vectorized_sum = np.matmul(np.transpose(weights), inputs) |
Girdiler ve ağırlıklar aynı boyutta vektörlerdir. Her ikisinin de sütun matris olduklarını varsayalım. Transpoz edilmiş ağırlıklar ile girdilere matris çarpımı uygulayabiliriz. Vektörizasyon olarak adlandırdığımız bu yaklaşım da for döngüleri ile dizayn ettiğimiz yapı ile aynı sonucu üretecektir.
Vektörizasyon 4 kat daha temiz kod yazmamızı sağlamaktadır. C++ dilinin yaratıcısı Bjarne Stroustrup’un da değindiği gibi yazdığımız kodun zarif etkin olmasını istememiz gayet doğal. Burada Audrey Hepburn’un zerafet geçmeyen tek güzelliktir sözü de aklıma geliyor.
Bu yaklaşım temiz kod yazımının ötesinde performans olarak 150 kat daha hızlı çalışmaktadır!
Bu yüzden de Barbara Fusinska, derin öğrenmeyi çok sayıda matris çarpımı olarak tanımlamakta.
Aslında bu sonuç makine öğrenmesi ile ilgilenen topluluğun neden Python dilini benimsediğini açıklamakta. Java, C# gibi üst seviye dillerde her ne kadar değişkenleri matris olarak tanımlayabilseniz de matris çarpımı için for döngüleri dizayn etmeniz gerekmekte. Python ise numpy kütüphanesi ile matris çarpımında üstün performans göstermekte. Benzer şekilde TensorFlow kütüphanesi de kendine ait güçlü matris çarpımı yeteneğine sahiptir. Buradan Python’un diğer dillerden daha hızlı olduğunu söylememiz çok doğru olmaz. Python eğer lineer cebiri kodunuza dökmeyi becerirseniz çok daha hızlı hale gelmektedir.
Matlab matris çarpımı konusunda her ne kadar python’dan daha hızlı olsa da veri transformasyonu, veri tabanı bağlantıları, servis entegrasyonu gibi konularda çok iyi olduğu söylenemez. Java ve C# gibi diller ise bu konularda başarılı iken matris çarpımı gibi konularda geride kalmaktadır. İşte bu noktada Python, nesneye dayalı programlar geliştirebileceğiniz veri tabanı ve servis entegrasyonu gibi konularda iyi olan güçlü bir hesaplama dilidir.
Modelinizin eğitimi haftalar alabilecekken eğitilmiş bir modelin tahmin süresi milisaniyelerdir. Bu sebeple eğitimin tensorflow ile yapılıp üretim ortamında java üzerinden tahminin yapıldığı örnek kullanımlar oldukça yaygındır.
Test
Birim testlerimiz bugün yazılım geliştirme ve devops süreçlerinin önemli bir kısmıdır. Öyle ki test güdümlü geliştirme (test driven development) bize kodu yazmadan önce testlerimizi yazma tavsiyesinde bulunur. Peki birim testler hangi koşullar altında yazılır? Programın dönmesini beklediğiniz cevaptan kesin eminseniz birim testler sizin için anlamlıdır. Ancak bu makine öğrenmesi yaşam döngüsüne pek uymamakta.
Çektiğiniz fotoğraflardan erkek kadın ayrımı yapan bir mobil uygulama geliştirdiğinizi varsayalım. Eğitim için size 100 resim vermiş olalım. Siz de öyle bir model geliştirdiniz ki bu resimlerin tamamını doğru şekilde sınıflandırabiliyorsunuz. Fakat size göstermediğim 100 farklı resimle uygulamanızı test ettiğim zaman ancak 30 tanesinin doğru sınıflandırıldığını görüyorum. Bu modelinizin hiç bir şey öğrenmediği sadece size ilk verdiğim 100 resmin cinsiyetini ezberlediği anlamına geliyor.
Uygulama ilk elinize geçen 100 resmin 70 tanesini doğru sınıflandırsaydı ve hiç görmediği örneklemlerde de başarı oranı bu değerlere yakın olsaydı daha başarılı bir uygulamaya sahip olduğunuzu söyleyebilirdik. İşte bu makine öğrenmesi problemlerinin en baş belası olan Türkçe’ye fazla öğrenme ya da ezberleme olarak çevrilebilecek olan overfitting problemidir. O kadar tehlikelidir ki siz tatmin edici değerler elde ettiğinizi düşünürken yakınında bile değilsinizdir. İşte bu sebeple ezberlemenin önüne geçmek için gerekirse modelimizin hata yapmasına izin vermemiz gerekiyor.
Birim testlerin doğrudan yöntemlerle neden makine öğrenmesi çalışmalarında uygun olmadığını anlamışsınızdır. Bunun yerinde biz eğitim validasyon ve çapraz validasyon testi şeklinde verimizi üçe bölerek genelde de 70% – 15% – 15% oranlarında veri setini dağıtarak modelimizi geliştiriyoruz. Model eğitim seti ile eğitilirken validasyon setine ait kayıp değerinin iterasyonlar boyunca azalıp azalmadığını gözlemliyor, eğitim setinin kayıp fonksiyonu azalırken validasyon setininki artmaya başlamışsa eğitimi orada kesiyoruz. Çapraz validasyon seti ise modelin validasyon setini ezberleyip ezberlemediğini teyit etmek için önem teşkil ediyor.

Veriye dayalı organizasyonlar
Büyük organizasyonlar CEO ya da COO’ya raporlayan CDO (Chief Data Officer) rolünü atamalara başlamış durumda. Bu rol veriye dayalı organizasyonlar için olmazsa olmaz. Yukarıdaki örneklerden de anlayacağınız üzere veri bilimi takımlarını geleneksel yazılımcı zihniyeti ile yönetmek çok zor.
Yazılım mühendislerinden kod yazmalarını bekleyebilirsiniz. Onlar için iyi tanımlanmış beklentirler mevcuttur. Halbuki veri bilimcileri zamanlarının büyük çoğunu modellerin tune edilmesi ile geçirmektedir. Örneğin bir nöral ağ yapısının dizaynı, girdi niteliklerinin belirlenmesi, probleme uygun aktivasyon fonksiyonun seçilmesi gibi şeyler. Çünkü en doğru dizaynı size verecek bir fonksiyon bulunmamaktadır (AutoML kavramını dışarıda tutuyorum). Veri takımlarının state-of-the-art olarak adlandırılan sanat seviyesindeki çabaları bu tür işlerden oluşmakta. Benzer şekilde veri mühendisleri, veri bilimcilerin çalışabileceği veriyi hazır etmeye çalışırken terabyte’lar mertebesinde veriyi bir ortamdan başka bir ortama transfer etmek zorundadır. Geleneksel bir yazılımcının çokça uygulamadığı prosedürler olduğunu anlayabiliyorsunuzdur.
Doğru iş için doğru araç
Veri takımları teknoloji yada programlama dili yerine çokça algoritmaları tartışmaktadır.

Makine öğrenmesi problemleri sıklıkla üç ana gruba ayrılmaktadır. Eğer probleminiz ne kadar sorusuna cevap veriyorsa, bir regresyon problemidir. Apple hisselerinin önümüzdeki hafta ne kadar olacağının tahmin edilmesi buna bir örnektir. Eğer probleminiz o mu yoksa bu mu sorusuna cevap veriyorsa bir sınıflandırma problemidir. Önceden de örnek verdiğimiz fotoğraftan erkek kadın tespiti buna bir örnek olabilir.
Regresyon veya sınıflandırma problemleri için tahminlerinizin doğruluğunu değerlendirebilirsiniz çünkü olması gerektiği gerçek değerlere vakıfsınızdır. Kedi resimlerinin sınıflandırılmasında hangi resimlerin kedi hangilerinin ise köpek olduğunu zaten biliyorsunuzdur. Burada resmin kedi mi yoksa köpek mi olduğunu ifade eden etiket değeri bir süpervizör tarafından hali hazırda etiketlenmiştir. Bu sebeple regresyon ve sınıflandırma problemleri gözetimli (supervised) öğrenmeye girmektedir.
Peki veri setinizde etiketler yoksa? Bir süpervizör bu resimleri daha önceden sizin için etiketlememişse ve bir şeyler öğrenmeniz bekleniyorsa gözetimsiz (unsupervised) öğrenme ile karşı karşıya kalırsınız. Genel yaklaşım veri setini kümelere bölerek çıkarımlar yapmaktır.
Regresyon, sınıflandırma ve kümeleme için farklı algoritmalar bulunmaktadır. Örneğin ID3 ve C4.5 karar ağacı algoritması sadece sınıflandırma problemleri için çalışmaktadır. Bu algoritmalara yıllarınızı vererek uzmanı olmuş olsanı bile bir regresyon problemi önünüze geldiğinde elinizde uygun bir araç bulunmayacaktır.
Burada yapay sinir ağlarını isviçre çakışına benzetebiliriz. Algoritmayı her türlü makine öğrenmesi taskına uygulamanız mümkündür. Tek yapmanız gereken ise algoritaya verinizi beslemektir. Regresyon, sınıflandırma ve kümeleme problemlerini çözebilirsiniz.
En sevdiğim makine öğrenmesi yöntemi nöral ağlardır. Bu benim favorim. En sevdiğim ikinci makine öğrenmesi yöntemi ise SVD’dir. Herkes bana gradient boosting ağaçları tercih etmiyor musun diye soruyor. Gradient boosting ağaçların mükemmel olduğunu biliyorum fakat ben en çok nöral ağları sonrasında da SVD’yi seviyorum – Francois Chollet
Makine öğrenmesi çalışmaları, matematik, kod ve iletişim yeteneklerine sahip olmayı gerektirir. Yazılımcılar geçmiş kodlama yetenekleri sebebiyle halen bu alan için en potansiyel yetenekler olarak görülmektedir. Tek ihtiyaçları zihniyetlerini kod bazlıdan matematik odaklı bir perspektife dönüştürmeleridir.
Bu yazı ilginizi çektiyse aşağıdaki webinar’a göz atmanızı tavsiye ederim.
Bu yazı “A Developer’s Guide to Machine Learning” yazısından Türkçe’ye çevrilmiştir.