Machine learning kavramını basitçe bir örnekle incelersek, yeni öğrenmeye çalıştığımız herhangi bir konuyu belli bir kaynaktan çalıştıktan ve konuya dair belirli çıkarımlarda bulunduktan sonra ilerleyen zamanlarda önümüze o konuya dair bir problem çıkarsa o problemin yarattığı bilinmeyene önceden yapılmış çıkarımlarla tahminde bulunma sanatıdır. Daha teknik açıdan bakmak gerekirse machine learning, matematiksel ve istatistiksel yöntemlerin kullanılmasıyla elde bulunan verilerden çıkarımlar yapıp, yapılan bu çıkarımları ileri süreçte ortaya çıkan problemin çözümüne tahminde bulunmak için kullanan bilimdir.
Günümüzün en sıcak teknoloji trendi olan Big Data’nın gelişimi ile beraber veri miktarının artması, machine learning için çok önemli bir kaynak oluşturmaktadır. Aynı zamanda machine learning Big Data içerisine gizlenmiş önemli verilerin gün yüzüne çıkarılması için önemli bir araçtır. Bu iki teknoloji birbiri ile mutualist bir ilişki içerisinde gelişmeye devam etmektedir.
Machine Learning algoritmalarına iki farklı şekilde yaklaşabiliriz bunlardan ilki Supervised Learning yani denetim, gözlem altında öğrenme yöntemidir. Basit olarak ifade edersek yol gösterici bir öğretmenin “Şu gibi bir durumla karşılaşırsan yapman gereken budur.” dediği yaklaşımdır. Mevcut durumları sağlayan fonksiyonlar üretilir ve öğrenme aşamasının sonlandığı varsayılır. Ardından daha değişik veriler ile kontrol aşamasına geçilir. Bu aşamada beklenen sonuçlar elde edilmez ise yeniden “Bu durumda şöyle davranman gerekiyor.” aşamasına dönülür.
Bu yöntemin kullanıldığı birkaç algoritmaya göz atalım.
1) Decision Trees
Karar ağaçları, kaynakların, risklerin, yapılacak tercihlerin, konulacak hedeflerin belirlenmesinde şansa bağlı olan karar noktalarının incelenmesini sağlayan tekniktir.
Yaklaşık olarak fotoğraftaki gibi bir yapıya sahip olan karar ağaçları, iç düğümlerine girdi alarak bu girdiler sonucunda bir dış düğüm (öneri) sunar. Çoğu zaman asgari sayıda evet/hayır sorusuna sahip iç girdilerden meydana gelmektedir. Mantıklı sonuca ulaşmak için sistematik bir yaklaşım imkanı sunmaktadır.
2) Naïve Bayes Classification
Naïve Bayes sınıflandırması olasılık ilkelerine göre tanımlanmış bir dizi hesaplama ile, sisteme sunulan verilerin sınıfını yani kategorisini tespit etmeyi amaçlar.
Naïve Bayes sınıflandırmasında sisteme belirli bir oranda öğretilmiş veri sunulur (Örn: 100 adet). Öğretim için sunulan verilerin mutlaka bir sınıfı/kategorisi bulunmalıdır. Öğretilmiş veriler üzerinde yapılan olasılık işlemleri ile, sisteme sunulan yeni test verileri, daha önce elde edilmiş olasılık değerlerine göre işletilir ve verilen test verisinin hangi kategoride olduğu tespit edilmeye çalışılır. Elbette öğretilmiş veri sayısı ne kadar çok ise, test verisinin gerçek kategorisini tespit etmek o kadar kesin olabilmektedir.
Bazı günlük hayat uygulamaları:
- Bir e-mail’in spam mı olduğunu belirleme
- Yazılmış makalelerin türünü ortaya koyma (teknoloji, spor vb.)
- Bir metin parçasını kontrol edip olumlu mu olumsuz mu olduğunu belirleme
- Yüz tanıma yazılımları
3) Ordinary Least Squares Regression
En küçük kareler yöntemi, birbiriyle ilişkilendirilmiş iki farklı fiziksel büyüklüğün birbirine olan matematiksel bağımlılığını, mümkün olan en gerçek sonuca ulaştıracak bir denklem halinde belirtmek amacıyla kullanılan gerileme yöntemidir.
Basitçe ifade etmek gerekirse X ve Y birbirine bağımlı fiziksel büyüklükler olsun. İkisi arasındaki ilişki Y = aX + b gibi bir denklemle ifade edilsin. Bizim amacımız a ve b değerlerini mümkün olduğu kadar gerçek değerlerine yaklaştırmaktır.
Yaklaştırma işlemi için önceden elde edilmiş (xi ve yi) veri çiftleri vardır. Bu değerleri kartezyen denklemde tek tek işaretleriz ve ardından üzerlerinden düz bir çizgi çekmeye çalışırız. Büyük olasılıkla hiçbir zaman böyle bir çizgi elde edemeyiz. Bizim amacımız bu noktada devreye girer ve veri çiftlerine mümkün olan en yakın uzaklıktaki çizgiyi tespit etmeye çalışırız.
En küçük kareler yöntemi, denklemden elde edilen Y değerleri ile ölçüm sonucu elde edilmiş gerçek Y değerlerinin farklarını bulup, karelerini hesaplayıp bu değeri mümkün olduğunca küçültmeye çalışır.
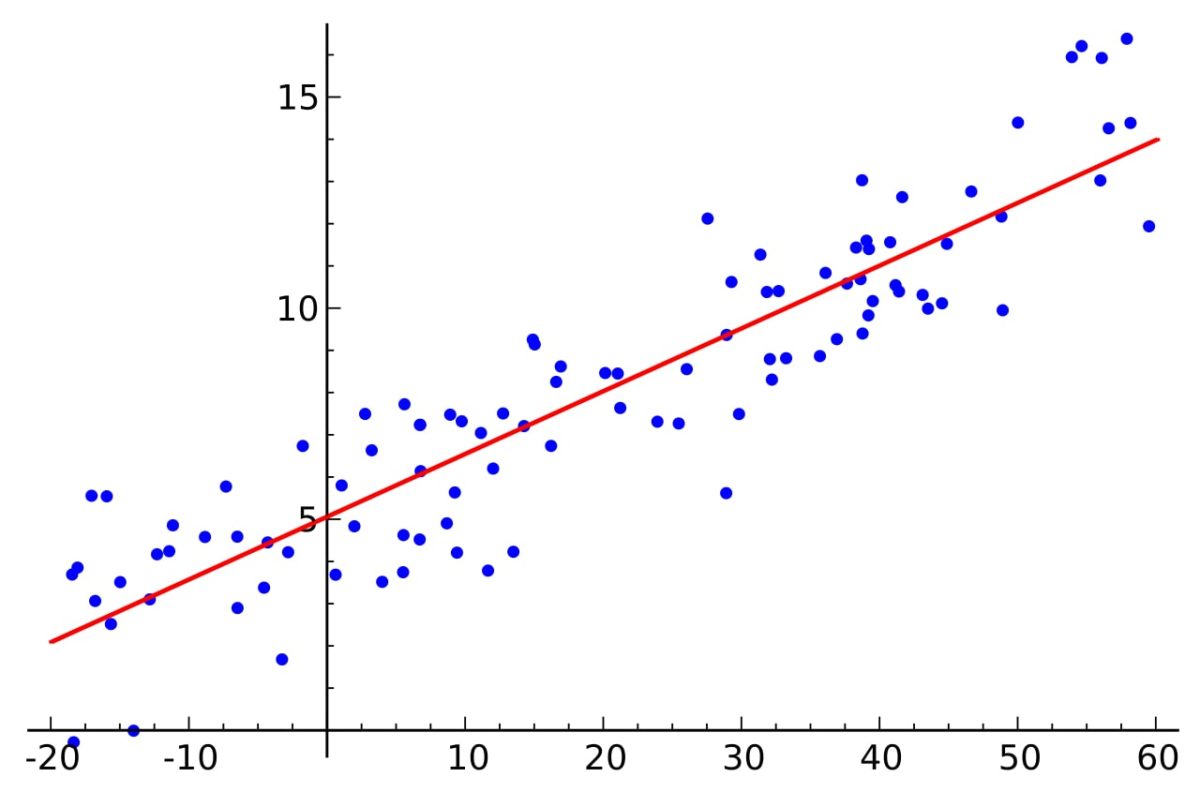 Yukarıdaki grafikte mavi noktalar testler sonucunda oluşmuş X ve Y değerlerini ifade eder. Kırmızı çizgi ise en küçük kareler yöntemi kullanılarak elde edilmiş en gerçeğe yakın denklemin oluşturduğu noktalar kümesini gösterir.
Yukarıdaki grafikte mavi noktalar testler sonucunda oluşmuş X ve Y değerlerini ifade eder. Kırmızı çizgi ise en küçük kareler yöntemi kullanılarak elde edilmiş en gerçeğe yakın denklemin oluşturduğu noktalar kümesini gösterir.
4) Logistic Regression
Logistic regression genel olarak bağımlı ve bağımsız değişkenler arasındaki ilişkiyi, en az değişken ile en iyi uyuma sahip olacak biçimde tanımlamayı hedefleyip, kabul edilebilir bir model kurar. Model sayesinde mevcut problemin hangi gruba ait olduğunun tespiti de yapılabilir.
Kullanım alanı olarak gerçek hayattaki hemen hemen her problem verilebilir.
Bir suç hakkında verilerin toplanıp analiz edildikten sonra suçun kimin tarafından işlendiğinin tespiti, sağlık verilerinin toplanıp ardından hastalığın ne olduğuna ve derecesine dair tespitler, günlük trafik akışına ait verilerin toplanıp hangi yolların hangi kullanıcılar tarafından daha çok kullanıldığı, hangi saatlerde en yoğun/en az yoğun olduğu tespiti gibi akla gelebilecek çoğu problemde kullanılır.
5) Support Vector Machines
Support Vector Machines de kümeleme/sınıflandırma problemleri için kullanılan bir yöntemdir. Sınıflandırma için iki farklı sınıfın arasına bir çizgi çekeriz. Bu sınır çizgisi iki farklı sınıfın üyelerine de en uzak bölge olmak durumundadır. SVM bu sınır çizgisinin çekilme biçimini belirler.
Öncelikle iki gruba da yakın iki farklı çizgi çizilir ardından bu çizgiler birbirlerine yakınlaştırılıp tek bir çizgi haline getirilmeye çalışılır.
Genel olarak elde bulundurulan uzayda sınıflandırma için lineer bir karar mekanizması bulunamamış ise, başka bir çok boyutlu uzaya taşınıp, lineer karar mekanizmasını elde etmek amacıyla kullanılır.
Machine learning algoritmalarında ikinci yaklaşım olan Unsupervised Learning (gözetimsiz öğrenme) metodu işaretlenmemiş veri üzerinden bilinmeyen bir yapıyı tahmin etmek için fonksiyon kullanır. Burada girdi verisinin hangi sınıfa ait olduğu belirsizdir. Bu metodun ortaya çıkardığı sonuçlardan, öncesinde bilgi verilmediği için, kesin doğruluk beklenmemektedir.
6) Clustering Algorithms
Demetleme algoritmaları olarak bilinirler. Demet, benzer nesnelerden oluşan grup anlamına gelir. Nesnelerin niteliklerinden faydalanarak veri içindeki benzerlikleri tespit ederek benzer verileri gruplama işlemidir.
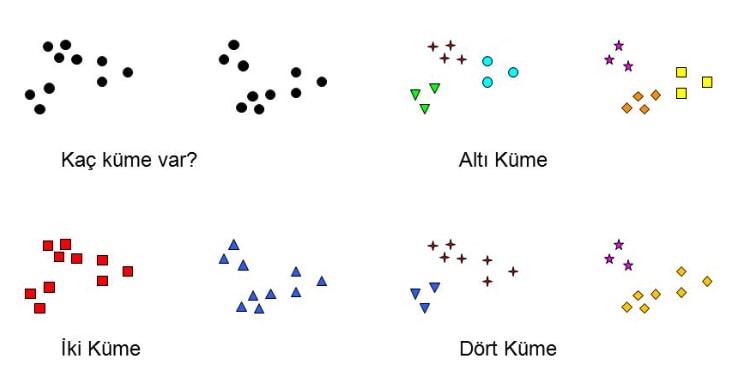
Oluşturulmuş hemen hemen her demetleme algoritması birbirinden farklıdır. Birkaç örnek kullanım aşağıdaki gibidir.
- Ağırlık merkezi temelli algoritmalar
- Bağlılık temelli algoritmalar
- Yoğunluk temelli algoritmalar
- Olasılıksal algoritmalar (Probabilistic)
- Boyut azaltma algoritmaları
- Sinirsel ağlar / Derin öğrenme algoritmaları
7) Principal Component Analysis
Temel bileşen analizi demetleme algoritmalara verdiğimiz örneklerden, boyut azaltma algoritmalarına girmektedir. Elde bulundurulan iki bilgi arasında bir bağlantı varsa bu bağlantı yardımıyla iki bilgiden birini elimizde tutarız diğerini kaybederiz. Sonrasında kaybedilen bilgi gerekli olursa bağıntı ve birinci bilgiyi kullanıp kaybedilen bilgiye erişebiliriz.
Bazı PCA uygulamaları öğrenim kolaylığı ve görsellik için verileri sıkıştırmayı hedefler.